
Let’s get acquainted if you haven’t followed us. We're ZURB.
If you've built software in the last two decades, you've probably touched our work: the Foundation framework, the design methods a generation of product teams learned from, and more recently Helio and Glare, our decision framework for product and design leaders. We've spent 25 years asking how teams make better product decisions faster.
Lately we've been chasing a different question, what does the robot need?
Radar is our latest experiment. It's in the same spirit as the playground pieces we've opened up over the years, made to learn in public and compare notes with other people building on these tools. We're sharing it because the interesting parts weren't the ones we expected, and if you're experimenting too, they might save you some time.
Radar is a working news publication for design and product leaders. It watches more than 60 sources, decides what matters, groups the signal into topics, writes the articles, illustrates them, and publishes daily. About 95% of it runs with no human involved.
Our goal is to surface new authors and perspectives to busy product and design leaders. We built it in two weeks, and it costs roughly 30 cents to produce an article (it's the least interesting thing we learned). Everything valuable about Radar lives in the 5% we chose not to automate, and that's the part we discuss in our back-and-forth.
Behind the scenes: it started on a Friday
Radar began as a Friday experiment. We were browsing around, half looking for inspiration, and landed on a question that seemed small… could we surface news for product and design leaders in a way worth reading? Niche, but a real audience, and concrete enough to poke at over a weekend.
First we had to figure out where the news even comes from. Ben talked it through with Claude, and the answer was old technology repurposed.
RSS feeds have been around forever, and they're still the cheapest way to pull a lot of links out of a lot of sites. So we curated a list of sources worth trusting and pointed the system at their feeds.
The first working prototype was up in a few hours. It used to be that a build like this would normally take a few weeks, and having something live the same afternoon changed how we worked on it. We went straight into design before we'd figured out the real user problem, which is not how we'd usually advise anyone to work, but the technology itself became the driver.
We just wanted to see what we could do with it. News seemed pretty low risk, especially given the costs of the build.
We wanted a living system, not a prompt
The idea we wanted to start implementing was loops. Most people's instinct with these tools is to prompt, read the result, and prompt again. We wanted something that kept running, where incoming links could be continuously indexed. We never re-pull the same one and then label it as a small, cheap model with tags like AI terminology, user needs, or machine learning concepts. Those tags let us curate the feed down to what's relevant.
From there the system works in stages.
Indexing and labeling first, then a daily job that groups related links into candidate topics. We like small stages, because each one is a place we can inspect, tune, or step into without breaking the chain.
The harder, more interesting problem was putting ourselves in the middle of that machine without disrupting it. We wanted a system that kept turning on its own and still left room for human judgment at the two points that mattered. That balance, automation running continuously with editors steering from inside it, is what we're really experimenting with, and Radar was a concrete way to try it.
We automated everything except two decisions
After some back-and-forth testing over two weeks we figured out a few pieces we wanted to keep under human control for now.
We landed on two places for humans, and only two.
- Humans decide which topics deserve coverage.
- Humans decide whether the writing meets the bar.
The machine does the watching, filtering, drafting, illustrating, and publishing.
If you're experimenting with these tools, that's the pattern we'd hand you. Map the workflow, find the two or three points where human judgment actually creates value, protect those, and let the machinery handle the rest. The failure modes we watched for were automating the judgment away, which produces confident garbage, and refusing to automate the machinery, which wastes the people you should be pointing at the judgment.
What the open web actually is
One finding worth passing along… when we scaled from a dozen hand-picked feeds to our full list, we learned that roughly 60% of what came in was noise: shopping deals, gadget guides, celebrity gossip. Content that could never serve a design leader.
If you point AI at "all the data" or "the whole market," budget for the fact that most of any real-world input stream is junk. The value comes from the filter that decides what's worth a reader's attention, not from ingesting more. We built ours around one question, would a busy product or design leader care, and could they act on it or hold a point of view. That question, not the model, is what makes Radar useful.
The judgment layer is a product, so we built it like one
Because the human judgment is the whole game, we built tooling around it.

A list of topics, with their ELO scores of 1400 - 1600 (the higher the better), labels that were automatically generated, highlighting the type of content.
Editors pick topics through a fast, game-like interface instead of a meeting, with a rating system that surfaces the strongest candidates and lets weak ones die and recombine into fresh topics over time. The feed became less of a queue that empties and more of an ecosystem with turnover.
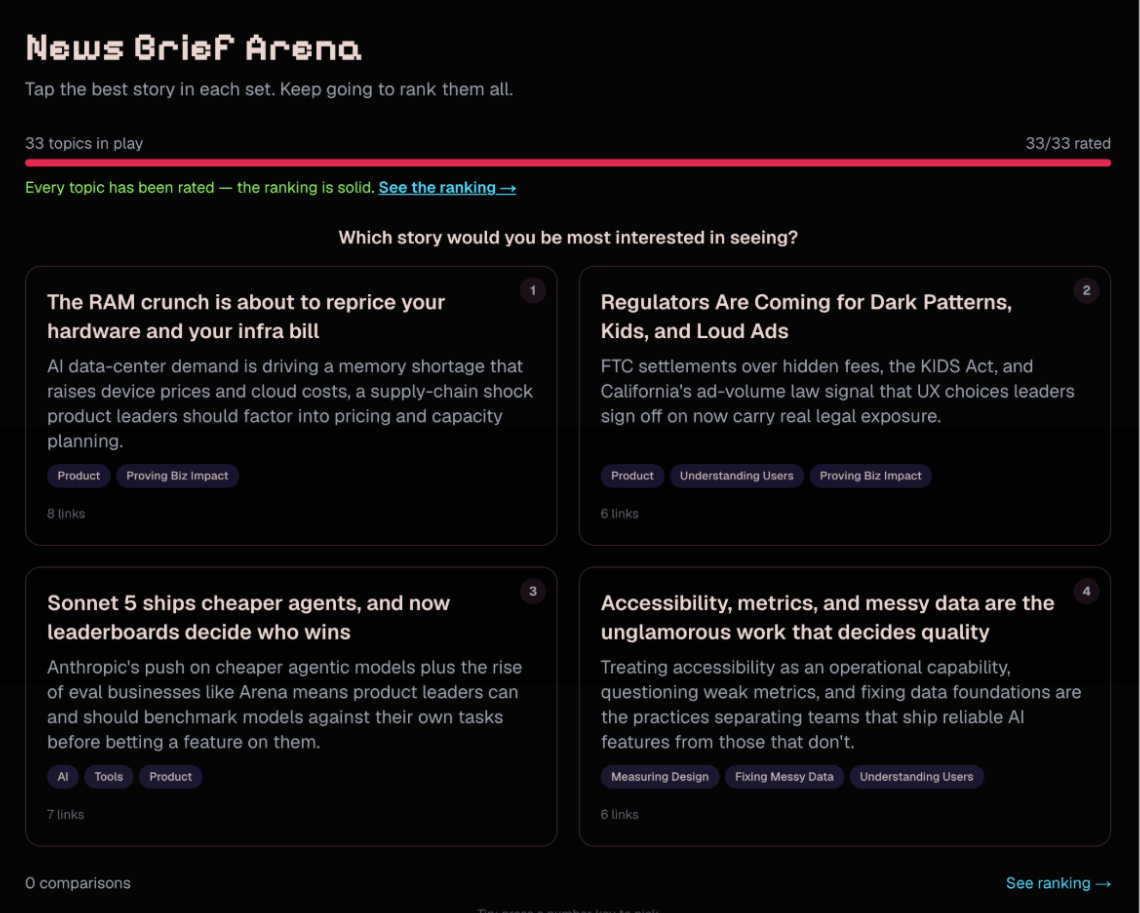
We could have made that a public, shareable game. We deliberately pulled it inside, editors only. It's the editorial desk, the place where human judgment steers the machine, and that belongs to the team. Readers get the articles.
The voice was the hardest part
Our first articles were accurate and well-sourced, but pretty much dead. Our own team called them encyclopedia entries. Fixing that took more work than any piece of the technical pipeline.
The single most useful change was shrinking the audience to one person, a busy leader who owns decisions. When we aimed at "everyone," the writing puffed up to impress a room. Naming one reader made it sharp: what changed, what the tradeoff is, what to bring to your next review. The rest is a growing list of rules we earned one cringe at a time, including a ban list of AI tells that gets longer every week.
We're being honest that it isn't finished. Titles are still our open problem. That's fine for an experiment. The parts that make Radar feel human are exactly the parts that took judgment and iteration, which is to say the parts a machine couldn't hand us.
What we'd tell a fellow builder
Almost nothing that made Radar work was a technical problem.
The pipeline took a few days. The two weeks went into calibration, done on and off as we found time to experiment: what counts as noise, how a team should choose, what makes writing feel machine-made.
Every one of those was a judgment we could only reach by shipping the wrong version first and reacting to it. It's something we tell our customers all the time, you have to ship a product to understand how it works.
We came out of this more excited than when we started, and that's the reason we're sharing it. The interesting creative work didn't disappear, it moved. It moved into the decisions we made next to the machine: what to cover, what to cut, what good even means here. If you've been waiting for a reason to experiment with these tools, that's it. The fun is in the decisions, and there are more of them than you'd think.
Radar is live at radar.zurb.com, built by the team behind Glare. If you're building something similar, or you want to argue with any of this, the forum is open.


